
머신러닝
Machine Learning Applications
Designed by Freepic
인공지능: 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술.머신러닝: 규칙을 프로그래밍 하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야딥러닝: 머신러닝 알고리즘 중에 인공신경망을 기반으로 한 방법들의 총칭.
개발 환경
머신러닝 분석에는 jupyter가 가장 잘 알려져 있습니다. Python 코드를 셀이라는 공간에 두고 셀 단위로 실행하고 결과를 확인할 수 있습니다. 셀은 코드와 텍스트 두 가지로 나뉘는데, 코드에는 파이선 코드를, 텍스트에는 마크다운 형식으로 설명을 작성할 수 있습니다
몇 가지 환경을 구축할수 있는데 아래의 3가지정도가 많이 쓰입니다.

Colab
Jupyter
VSCode
Jupyter는 인터렉티브 컴퓨팅을 할 수 있는 웹 어플리케이션입니다. 로컬 컴퓨터에 설치하여 사용할 수 있고 컴퓨터의 리소스를 사용합니다. 여러가지 extension도 사용 가능합니다. JupyterLab 도 참고해주세요.
colab은 클라우드 웹 클라우드에서 코드를 작성하고 실행할 수 있습니다. 인터넷 접속만 된다면 어디서든 사용할 수 있고, 왠만한 라이브러리는 모두 설치가 되어있습니다. 다양한 머신러닝 모델들이 colab으로 노트북을 공유하기도 합니다. 구글의 리소스를 사용하게 됩니다. 하지만 길게 이용하면 (특히 GPU) 세션이 제한될수 있습니다. colab pro를 이용한다면 오래 이용할 수 있습니다.
VSCode는 통합 개발 환경으로 개발 환경을 GUI로 이용할 수 있는 도구입니다. VSCode에서 여러 언어로 개발환경 구축이 가능하고 jupyter 또한 사용할 수 있습니다. 따로 jupyter를 따로 실행시킬 필요도 없고 extension 설치도 간편합니다.
Colab 예시
코랩은 아래 링크에서 이용이 가능합니다
파일 > 새 노트를 진행하면 아래와 같은 화면이 나타납니다.
colab의 사용법은 위 링크에 처음 접속하면 나타나는 Colab 시작 페이지를 보시면 사용하시는데 어려움은 없을 것 같습니다.
첫 머신러닝
어떤 물고기가 주어졌을 때 이 친구가 도미인지 아닌지 알아내는 머신러닝 모델을 만들어보겠습니다.
물고기의 길이, 무게 데이터가 있고,
물고기는 도미와 빙어가 있습니다.
1 | bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, |
분포 확인하기
도미와 빙어의 길이,무게 분포
어떻게 분류하면 좋을까요?
여기서는 K-Nearest Neighbors (KNN) 알고리즘을 이용해 구분해보겠습니다.
실습은 scikit-learn 라이브러리를 이용합니다.
머신러닝을 진행할 때 단계는 데이터 전처리, 훈련, 예측으로 진행됩니다.
데이터 전처리는 모델이 학습할 수 있는 형태의 데이터로 변환하거나, 불필요 데이터 정제 등의 이유로 진행합니다.
데이터 전처리
길이와 무게 데이터를 scikit learn에서 학습할 수 있는 2차원 데이터로 변환하였습니다. -> fish_data
모델이 학습할 정답 데이터는 도미는 1, 빙어는 0의 1차원 배열로 지정하였습니다. -> fish_target
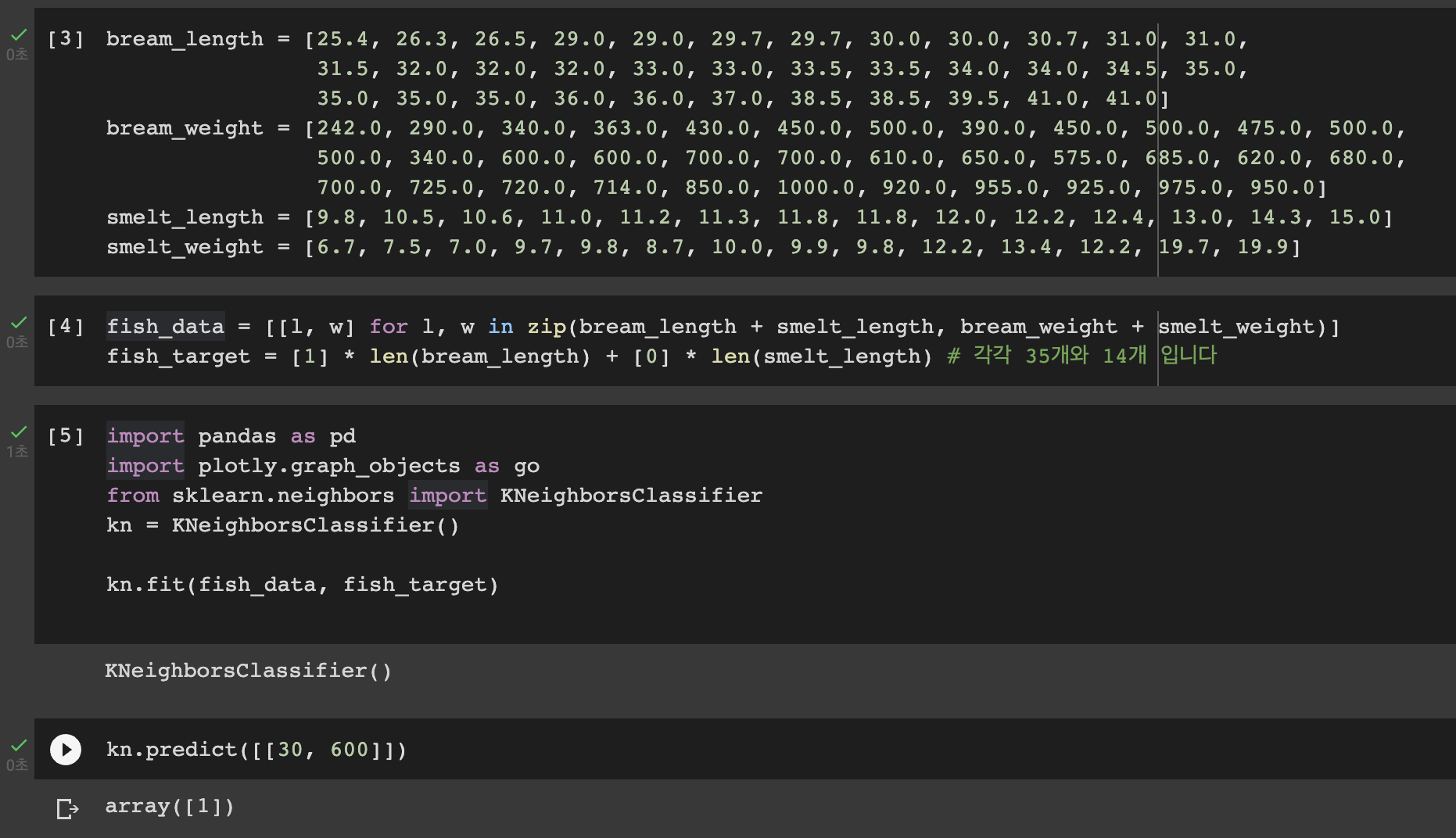
1 | fish_data = [[l, w] for l, w in zip(bream_length + smelt_length, bream_weight + smelt_weight)] |
모델을 생성하고 훈련시켜보기
1 | # 모델 불러오기 |
훈련까지 마쳤습니다.
아래의 미지의 물고기가 있습니다. 모델이 이 녀석을 어떻게 분류할지 봅시다.
- 길이: 30
- 무게: 600
- 종류: ?
도미와 빙어의 길이,무게 분포
데이터 분포에서 보았을 때, 직관적으로도 이 물고기는 아마도 도미일 것입니다.
예측해서 결과를 확인해보겠습니다.
예측해보기
1 | kn.predict([[30, 600]]) |
array([1]) 이라는 결과가 나왔습니다.
도미는 1, 빙어는 0으로 정답을 지정하였으므로, 이 물고기는 도미로 예측되어 결과가 나왔습니다.
오늘은 머신러닝을 KNN을 이용해 모델을 학습시키고 결과를 예측하는 과정을 간단히 정리하였습니다.
지금까지의 과정을 Colab에서도 같이 진행할 수 있습니다.
Colab 실습 과정
참고로,
이번에 사용한 K-NN은 데이터를 저장하고 가장 가까운 5개의 데이터의 정답을 다수결로 결정하여 예측값을 반환하는 모델입니다. (특별한 계산은 없습니다)
이에 대한 자세한 원리에 대해서는 아래의 영상을 참고 부탁드립니다.
읽어주셔서 감사드립니다.