

Fashion MNIST
Keras를 이용한 Fashion MNIST 데이터의 Classification을 해보겠습니다. 오늘 사용될 데이터는 Fashion MNIST입니다. 이는 핸드라이팅으로 만든 6만장의 훈련세트 와, 1만장의 테스트세트로 구성된 이미지 데이터입니다.
데이터 불러오기
1 | from tensorflow import keras |
데이터는 28x28로 이루어진 이미지입니다.
옷을 10개만 확인해보면 이미지는 다음처럼 생겼습니다.

우선 LogisticRegression으로 먼저 분류를 해보겠습니다.
1 | # 255로 나누어 정규화 하고 1차원 배열로 변환. |
성능이 0.82 정도로 나타납니다. 아주 좋지는 않습니다.
LogisticRegression으로 분류했으므로, 선형방정식을 학습했을 것입니다. 여기서는 28x28의 이미지를 1차원 배열로 만들어서 입력했으므로 다음과 같은 방정식이 있을 것입니다.
$ \begin{align} z_{1} = w_{1,1}*\text{pixel}_1 + w_{2,1}*\text{pixel}_2 + ... + w_{784,1}*\text{pixel}_{784} + b_1 \\\ z_{2} = w_{1,2}*\text{pixel}_1 + w_{2,2}*\text{pixel}_2 + ... + w_{784,2}*\text{pixel}_{784} + b_2 \end{align} $
$ z_1 $, $ z_1 $ 은 각각 1번 째, 2번 째 라벨에 대한 값입니다. 그리고 $ w_{픽셀,라벨} $는 가중치이고 $ b $ 는 절편입니다.
티셔츠에 대해 각 특성 (픽셀)에 가중치를 곱하여 절편과 함께 모두 더한 값이 $ z_{1} $ 입니다. 바지, 신발, 원피스, 등등 도 같습니다.
그림으로는 아래처럼 나타낼 수 있습니다.
LogisticRegression 시각화
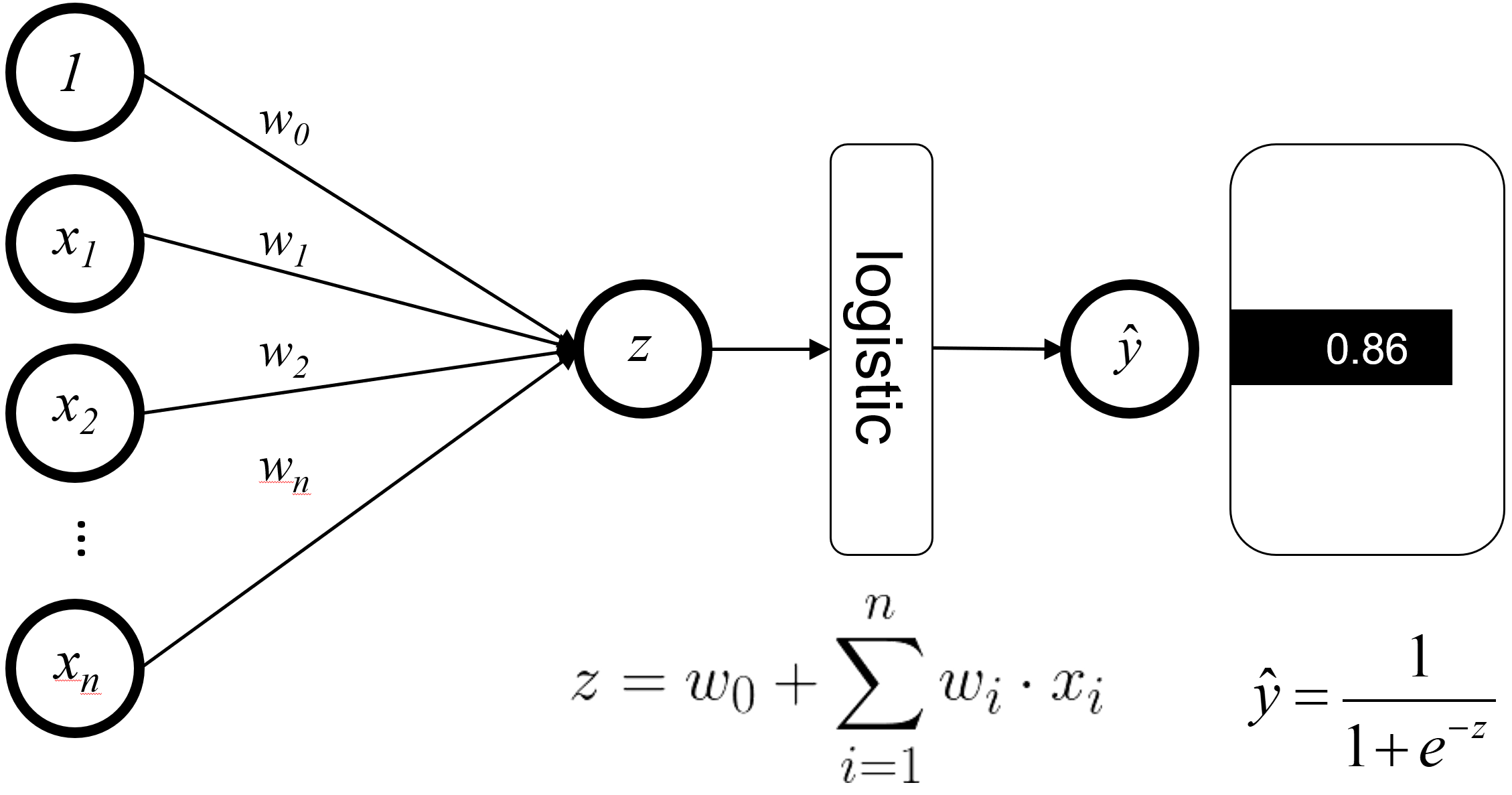
왼쪽의 x는 픽셀값입니다. 가중치와 곱해져서 z로 합쳐지고, 로지스틱 함수에 의해 y값이 산출됩니다. 이는 인공 신경망이 작동하는 원리와 비슷합니다.
인공신경망 시각화
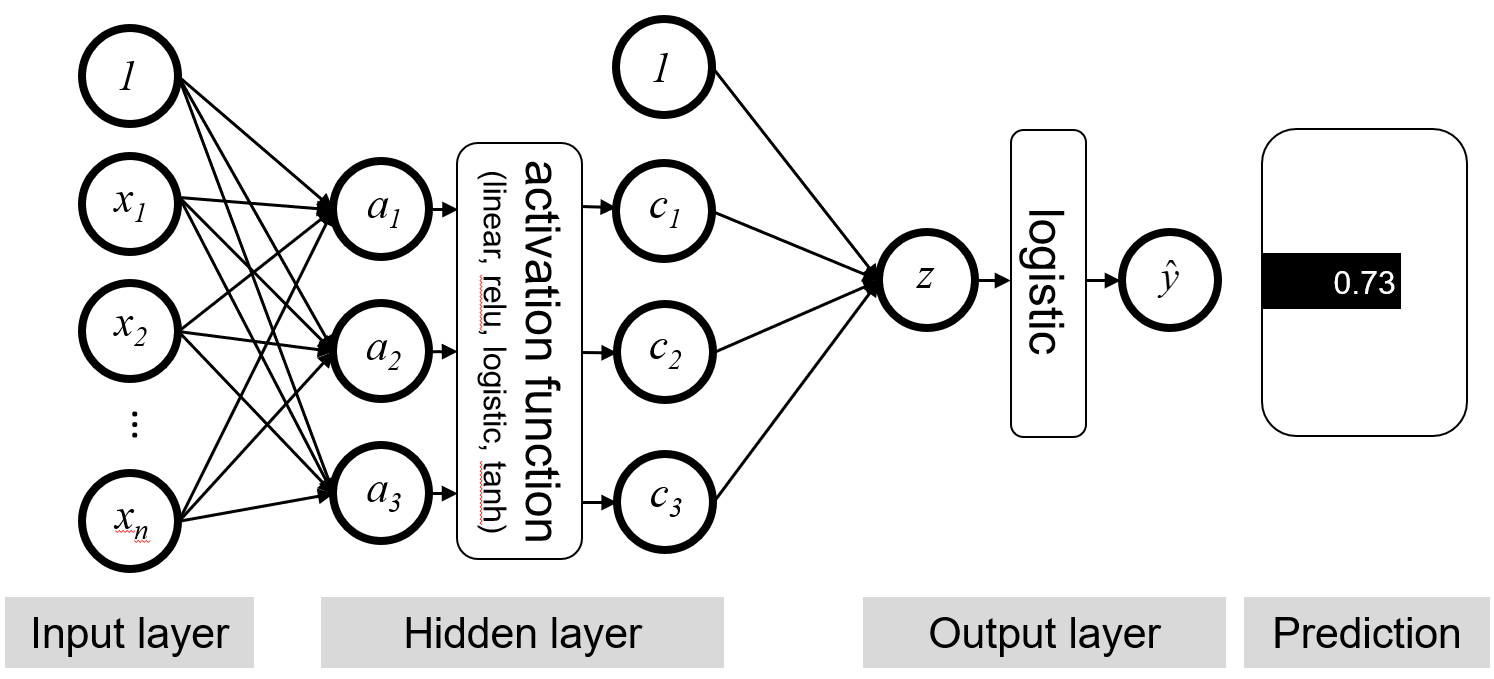
위에서 Hidden Layer를 제외한다면 거의 같은 모양입니다. 인공신경망에서는 몇가지 용어가 있는데 정리하면 다음과 같습니다.
- $ z $ 값을 계산하는 단위를 뉴런 neuron이라 합니다. 유닛Unit이라 부르기도 합니다.
- x값이 들어오는 층을 입력층Input Layer라 합니다.
- 최종 값을 만드는 층을 출력층Output Layer라 합니다.
케라스Keras
-
케라스는 딥러닝 프레임워크로 텐서플로의 고수준 API입니다.
-
딥러닝과 머신러닝의 차이 중 하나는 GPU를 사용한다는 것입니다. GPU는 행렬 연산에 최적화되어 있기 때문어서, 인공신경망에 큰 도움이 됩니다. nvidia에서 차이를 보여주기 위한 예시도 있습니다. 출처
CPU

GPU

-
케라스 프레임워크로써 텐서플로를 backend로 사용합니다. GPU연산은 텐서플로가 직접합니다. 또한 씨아노, CNTK 등도 backend로 사용할 수 있습니다.
-
여기서는 텐서플로를 backend로 케라스를 사용합니다.
keras로 패션잡화를 다시 분류해보겠습니다.
데이터 전처리
1 | from tensorflow import keras |
밀집층 만들기
밀집층Dense Layer는 케라스에서 기본이 되는 레이어입니다. 위에서 확인한 패션 MNIST 데이터의 크기는 28x28 = 784로 784개의 feature가 10가지 옷 종류인 z1 ~ z10으로 이어집니다. 784x10 = 7,840 개의 선으로 이어져 있습니다.
좌/우 뉴런이 모두 연결되어 있는 것을 완전 연결층Fully connected layer라고 합니다.
밀집층은 다음처럼 불러올 수 있습니다.
1 | dense = keras.layers.Dense(10, activation="softmax", input_shape=(784,)) |
- 10은 positional argument로, 뉴런의 개수를 의미합니다.
- activation은 뉴런 출력에 적용할 함수를 입력합니다. 결과계산에 적용하게 되는 활성화 함수activation function입니니다.
- input_shape는 인풋 데이터의 형태를 의미합니다.
모델은 다음처럼 지정할 수 있습니다.
1 | model = keras.Sequential(dense) |
- 모델을 지정하고 compile을 해주어야 하는데, 손실함수의 종류를 지정해줘야합니다.
- 케라스의 loss function
- 이진 분류는 binary_crossentropy라고 부릅니다.
- 다중 분류는 categorical_crossentropy로 부릅니다.
- 이진 분류는 양성 클래스와 음성 클래스에 대한 cross entropy를 계산하지만, 다중분류는 여러 클래스에 대한 출력층 뉴런이 존재하고, 10개 클래스에 대한 확률을 만들게 됩니다. 10개중 하나의 클래스만이 정답이므로 정답은 1 나머지는 0으로 만들어서 각 확률에 곱해준다면, 타겟에 맞는 뉴런의 출력만 남기게 됩니다. 클래스를 0, 1로 표현하게 해주는 것을 원-핫 인코딩이라고 합니다.
- sparse_categorical_crossentropy는 원-핫 인코딩이 필요없이 정수형으로 된 타겟값을 받고 cross entropy를 계산해주는 손실함수입니다.
- (참고) 원-핫 인코딩이 된 데이터를 사용하려면 loss function으로 categorical_crossentropy를 이용하면 됩니다.
- metrics
- 모델이 훈련할 때마다 에포크 손실값을 출력하는데, 에포크마다 손실 변화에 따른 정확도같이 확인하기 위해 지정해 줍니다.
훈련
1 | model.fit(train_scaled, train_target, epochs=5) |
성능 확인
1 | model.evaluate(val_scaled, val_target) |
검증세트의 성능은 훈련세트보다는 조금 점수가 낮은것이 일반적입니다.
성능은 85% 정도가 나타났습니다.
은닉층 추가해보기
위에서는 1개의 층만 사용했지만, 이번에는 층을 2개 추가해보겠습니다. 입력층과 출력층 사이에 밀집층이 하나 더 추가된 것이고, 이런 층을 은닉층hidden layer라고 합니다.
- 은닉층도 활성화 함수를 지정해줘야합니다. 대표적으로 시그모이드, 렐루 함수가 있습니다.
- 은닉층에 활성화 함수를 지정하는 이유는, 선형적 산술 계산만 하는 것이 아닌 비선형적으로 만들어주기 위함입니다.
- 참고) 회귀에서는 임의의 숫자를 예측해주므로 활성화 함수를 적용할 필요가 없습니다.
모델 만들기
1 | dense1 = keras.layers.Dense(100, activation = "sigmoid", input_shape = (784, )) |
모델에 대한 정보 확인
1 | model.summary() |
- 레이어 이름, 클래스, 출력크기, 모델 파라미터 수가 나타납니다.
- Output 형태에 None이 있는 이유
- fit을 할 때, 훈련데이터를 모두 사용하지 않고 잘게 나누어 여러번 경사 하강법을 거칩니다. -> 미니 배치 경사하강법
- 미니배치의 크기는 32로, fit 메서드를 수행할 때 batch_size로 바꿀 수 있습니다.
- 따라서 현재 None의 의미는 샘플 개수를 고정하지 않고 어떤 배치 크기에도 유연하게 대응하겠다는 의미입니다.
- Param은 784개 feature로 100개의 출력을 하므로 모든 조합에 대한 weight와 100개 출력에 대한 절편도 존재하므로, 78400 + 100=78500개의 모델 파라미터가 있다고 나타나게됩니다. 2번 째 층도 같습니다.
참고) 모델을 만드는 다른 방법
1 | # 1. 모델 생성시 dense객체 직접 추가 |
훈련
1 | model.compile(loss = "sparse_categorical_crossentropy", metrics = "accuracy") |
은닉층을 추가하니 87%으로 성능이 올랐군요. 이번에는 이미지 분류에 많이 사용되는 활성화 함수인 ReLU를 사용해보죠.
ReLU

- 시그모이드는 어떤 값이 들어와도 0, 1로 분류를 해주지만, 낮은 값이 들어올수록 그래프가 누워있어서 올바른 출력을 만드는데 빠지 못합니다.
- 렐루함수는 이를 개선시키기 위해 나타났고, 한쪽 입력에서는 없는것처럼 입력을 통과시키고 값을 0으로 만들어버립니다.
1 | model = keras.Sequential() |
- 첫 Dense Layer에 활성화 함수로 relu를 입력해주었습니다.
- 우리는 지금까지 28x28이미지를 1차원으로 만들어 인풋을 넣어주었습니다.
Flatten 층은 이를 알아서 변환해주는 층입니다. (변환만 해주므로, 신경망의 깊이가 늘어난것은 아닙니다.)
케라스에서는 입력데이터에 대한 전처리 과정을 될수 있으면 모델에 포함합니다.
Flatten 층이 있으므로 reshape로 1차원 배열을 만드는 과정 없이 해보겠습니다.
데이터 전처리
1 | (train_input, train_target), (test_input, test_target) = \ |
훈련
1 | model.compile(loss = "sparse_categorical_crossentropy", metrics = "accuracy") |
성능이 88%입니다. 조금이지만 렐루 함수의 영향으로 성능이 올라갔습니다.
옵티마이저
신경망의 가중치와 절편을 학습하기 위한 알고리즘 (혹은 방법) 입니다. 이번에 등장한 하이퍼파라미터는 다음과 같이 존재할 수 있습니다.
- 은닉층의 개수
- 은닉층의 뉴런 개수
- 활성화 함수
- 층의 종류
- 미니배치 경사하강법 사용시 배치 사이즈
- epochs 수
케라스에는 여러 경사하강법 알고리즘이 구현되어 있습니다.
- SGD - 기본 경사하강법
- 네스테로프 모멘텀 - 기본 경사하강법
- RMSprop - 적응적 학습률
- Adam - 적응적 학습률
- Adagrad - 적응적 학습률
모멘텀은 이전의 그레이디언트를 가속도처럼 사용합니다. 적응적 학습률 옵티마이저는 모델이 최적점에 갈 수록 학습률을 낮추는데, 이렇게 하면 안정적으로 최적점에 수렴할 가능성이 높습니다.
중간 점검
여기서 몇가지 중간 점검을 해보겠습니다. 오늘은 문제가 많습니다.
-
인공신경만의 입력 특성이 100개이고 밀집층에 있는 뉴런의 수가 10개일 때, 필요한 모델파라미터의 수는?
-
케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경만이 이진 분류 모델이라면, activation 매개변수에 어떤 활성화 함수를 넣어야 할까요?
-
케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는 무엇인가요?
-
정수 레이블을 타겟으로 가지는 다중 분류 문제일 때 케라스 모델의 compile() 메서드에 지정할 손실함수로 적절한 것은?
-
다음 중 모델의 add() 메서드 사용법이 올바른 것은?
1️⃣ model.add(keras.layers.Dense)
2️⃣ model.add(keras.layers.Dense(10, activation = “relu”))
3️⃣ model.add(keras.layers.Dense, 10, activation = “relu”)
4️⃣ model.add(keras.layers.Dense), (10, activation = “relu”)) -
크기가 300x300인 입력을 케라스 층으로 펼치려고 하는데, 어떤 층을 사용해야 할까요?
-
이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는 무엇일까요?
-
다음 중 적응적 학습률을 사용하지 않는 옵티마이저는 무엇인가요?
1️⃣ SGD
2️⃣ Adagrad
3️⃣ RMSprop
4️⃣ Adam
…
-
인공신경만의 입력 특성이 100개이고 밀집층에 있는 뉴런의 수가 10개일 때, 필요한 모델파라미터의 수는?
- feature, target에 따라 가중치가 존재하므로 100x10
- 타겟 절편의 수 10
- 따라서 모델 파라미터의 수는 1,010
-
케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경만이 이진 분류 모델이라면, activation 매개변수에 어떤 활성화 함수를 넣어야 할까요?
- 이진 분류에서는 보통 sigmoid 함수를 사용합니다.
-
케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는 무엇인가요?
- compile() 메서드에서 loss과 metric 파라미터로 지정할 수 있습니다.
-
정수 레이블을 타겟으로 가지는 다중 분류 문제일 때 케라스 모델의 compile() 메서드에 지정할 손실함수로 적절한 것은?
- "sparse_categorical_crossentropy"는 정수형 타겟 값으로 cross entropy를 계산해줍니다.
-
다음 중 모델의 add() 메서드 사용법이 올바른 것은?
1️⃣ model.add(keras.layers.Dense)
2️⃣ model.add(keras.layers.Dense(10, activation = “relu”)) ⭐️
3️⃣ model.add(keras.layers.Dense, 10, activation = “relu”)
4️⃣ model.add(keras.layers.Dense), (10, activation = “relu”)) -
크기가 300x300인 입력을 케라스 층으로 펼치려고 하는데, 어떤 층을 사용해야 할까요?
- Flatten 층을 사용하면 인풋 데이터를 펼치는 등의 전처리를 수행할 수 있습니다.
-
이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는 무엇일까요?
- ReLU는 시그모이드를 개선하기 위해 나왔고 이미지분류에서 성능이 좋아 널리 사용됩니다.
-
다음 중 적응적 학습률을 사용하지 않는 옵티마이저는 무엇인가요?
1️⃣ SGD ⭐️
2️⃣ Adagrad
3️⃣ RMSprop
4️⃣ Adam
오늘은 인공 신경망의 개요에 대해 알아보았습니다.
읽어주셔서 감사합니다👋