
Logistic Regression
Logistic regression은 선형 방정식을 이용한 분류 알고리즘입니다. Linear regression 처럼 변수의 상과관계를 표현하는 방정식을 만들지만, 각각의 클래스에 속할 확률을 예측하는 것이 목적입니다.
그래서 선형 방정식을 학습한다는 것은 이전에 보여드린 Linear Regression과 같지만, 결과는 0 ~ 1사이의 확률로 표현하여 합니다.
예를 들어, 아래와 같은 생선의 종류, 무게, 길이, 대각선, 높이, 두께 데이터가 있고, 생선의 종류의 확률을 예측하는 모델을 만든다고 해보겠습니다.
| Species | Weight | Length | Diagonal | Height | Width |
|---|---|---|---|---|---|
| Bream | 242 | 25.4 | 30 | 11.52 | 4.02 |
| Bream | 290 | 26.3 | 31.2 | 12.48 | 4.3056 |
| … | … | … | … | … | … |
| Smelt | 19.7 | 14.3 | 15.2 | 2.8728 | 2.0672 |
| Smelt | 19.9 | 15 | 16.2 | 2.9322 | 1.8792 |
선형 방정식은 다음 처럼 학습할 것입니다.
z = a * Weight + b * Length + c * Diagonal + d * Height + e * Width + f
a, b, c, d, e는 가중치를 나타내고, f는 절편입니다.
- z는 주어지는 생선 데이터에 따라 무엇이든 나올 수 있습니다.
- 하지만 확률을 예측해야 하므로, z에 따라 확률로 나타내야합니다.
- 이를 가능하게 해주는 것이 Sigmoid Function입니다. (Logistic Fuction이라고도 함)

Sigmoid Function
- z값이 커질 수록 1을, 작을수록 0을 나타냅니다.
- z에 따라 표시하면 아래과 같습니다.
scikit-learnd에서도 LogisticRegression으로 제공하고 있습니다. Binary logistic regression과 multinomial logistic regression을 할 수 있습니다.
Binary Classification
Logistic regression을 이용해 2가지 클래스에 대한 분류를 진행해보겠습니다.
1. 데이터 전처리
1 |
|
2. Bream과 Smelt의 이중분류 해보기
1 | # 데이터에서 Bream과 Smelt 데이터 분리 |
3. LogisticRegression 사용해보기
1 | from sklearn.linear_model import LogisticRegression |
학습
linear regression과 마찬가지로 주어진 데이터의 변수들에 대한 선형 방정식을 학습합니다.
lr.coef_와 lr.intercept_ 에 다음처럼 가중치 (혹은 계수)와 절편이 있습니다.
1 | print(lr.coef_) |
lr.coef_의 결과는 입력된 train데이터에 따라 Weight, Length, Diagonal, Height , Width의 가중치입니다.
따라서 방정식은 다음과 같습니다.
z = (-0.4037798) * Weight + (-0.57620209) * Length + (-0.66280298) * Diagonal + (-1.01290277) * Height + (-0.73168947) * Width + (-2.16155132)
예측
train 데이터의 5개를 predict를 하였을 때, 'Bream', 'Smelt', 'Bream', 'Bream', 'Bream'으로 나타났습니다.
예측한 확률을 predict_proba을 이용해 확인하면 다음과 같습니다.
1 | lr.predict_proba(train_bream_smelt[:5]) |
- predict_proba의 결과로 5개의 데이터셋에 대한 확률을 2개씩 내었는데, 주어진
class의 순서에 따라 확률을 표시합니다. - class 의 순서는
lr.classes_로 보면 첫 번째는Bream, 2번 째는Smelt입니다. - 안에서 일어나는 일은, 위에 학습된 선형 방정식에 따른 z값을 얻고, sigmoid 함수를 통해 0~1 사이의 값으로 변환이 가능합니다.
z 값 계산
1 | decisions = lr.decision_function(train_bream_smelt[:5]) |
Sigmoid를 이용한 확률 계산
1 | from scipy.special import expit |
실습을 위해 선형방정식을 이용해 직접 계산해도 같은 값이 나옵니다.
1 | def make_decision(dataset): |
다중 분류
scikit learn의 LogisticRegression은 기본적으로 규제와 최대 반복수가 정해져 있습니다. 파라미터 기본값은 다음과 같습니다.
1 | class sklearn.linear_model.LogisticRegression( |
여기서 C는 Inverse of regularization strength 으로 릿지 회귀에서는 alpha가 커질 수록 규제가 강해졌지만, 여기서는 반대로 (inverse) 값이 작을 수록 규제가 커집니다.
max_iter는 Maximum number of iterations taken for the solvers to converge 으로, 훈련을 하는 반복수입니다. 반복이 부족하다면 학습이 제대로 되지 않을 수 있고, 경고가 발생합니다.
자세한 설명은 공식문서에 있습니다.
실습
이번엔 여러개 클래스에 대해 예측을 해보겠습니다.
생선의 종류는 ‘Bream’ ‘Pike’ ‘Smelt’ ‘Perch’ ‘Parkki’ ‘Roach’ 'Whitefish’으로 7가지입니다.
| Species | Weight | Length | Diagonal | Height | Width |
|---|---|---|---|---|---|
| Bream | 242 | 25.4 | 30 | 11.52 | 4.02 |
| Bream | 290 | 26.3 | 31.2 | 12.48 | 4.3056 |
| … | … | … | … | … | … |
| Smelt | 19.7 | 14.3 | 15.2 | 2.8728 | 2.0672 |
| Smelt | 19.9 | 15 | 16.2 | 2.9322 | 1.8792 |
이번에는 규제를 완화하여 20으로 하고, max_iter는 기본값 100보다 충분히 주기 위해 1000으로 지정하겠습니다.
1 | lr = LogisticRegression(C = 20, max_iter = 1000) |
이번엔 데이터셋에 주어진 생선의 종류를 모두 사용하여 학습하였습니다.
훈련 데이터셋과 테스트 데이터셋의 성능이 overfitting이나 underfitting없이 나타나는 것 같습니다.
이번에는 테스트셋 5개의 예측결과, 예측된 확률을 살펴보겠습니다.
1 | print(lr.predict(test_scaled[:5])) |
- predict_proba의 결과를 보면 예측할 클래스 7개에 대한 확률을 각각의 데이터에 대해 보여줍니다.
- 그리고 binary logistic regression에서 말씀드린 것 처럼, class의 순서에 따라 확률을 표시합니다.
- 예측된 방정식을 보면 다음과 같습니다.
1 | print(lr.coef_.shape) |
7개의 class에 대한 5가지 feature 이므로 방정식의 크기 또한 다릅니다. 절편 또한 7개로 되어있습니다. multinomial logistic regression에서는 class마다 z값을 하나씩 계산합니다.
그러면 7개의 z값이 존재합니다. binary regression에서는 하나의 z값으로 두개를 분류했는데, 여기서는 어떻게 분류할까요?
scikit learn의 predict_proba의 설명을 보면 다음과 같습니다.
The returned estimates for all classes are ordered by the label of classes.
For a multi_class problem, if multi_class is set to be “multinomial” the softmax function is used to find the predicted probability of each class. Else use a one-vs-rest approach, i.e calculate the probability of each class assuming it to be positive using the logistic function. and normalize these values across all the classes.
- multinomical의 경우에는 softmax 함수를 사용합니다.
- softmax는 7개의 z값을 모두 합친 값이 1이 되도록 하여 확률로 변환합니다. 각각의 값에 모두 합친 값을 나누어 줍니다.
이번에도 구해진 z값을 softmax를 이용해 계산해서 같은 값인지 확인해보겠습니다.
5개 데이터의 대한 7개 z값은 다음과 같습니다.
1 | decision = lr.decision_function(test_scaled[:5]) |
scipy의 softmax함수를 이용해 계산했을 때, predict_proba의 결과와 같음을 볼 수 있습니다.
1 | from scipy.special import softmax |
여기서 중간점검을 한번 해보겠습니다.
Logistic regression에서 이진 분류의 확률을 출력하기 위해 사용하는 확률은 무엇일까요?
답은 Sigmoid함수입니다. 이진 분류에서는 선형 방정식을 통해 계산된 z값을 두가지 클래스 중에 확정해야 하는데,
값이 작을수록 0을 나타내고 값이 클 수록 1을 나타내는 sigmoid 함수를 이용하면 클래스의 확률을 0, 1에 가깝게 예측할 수 있습니다. 0.5를 기준으로 높으면 1, 낮으면 0 으로 분류가 가능하므로 두가지 클래스에서 하나를 선택할 수 있는 확률이 구해집니다.
Stochastic Gradient Descent (SGD)
지금까지의 방법은 모델을 선언하고, 학습시키고, 예측하는 방법이었습니다. 만약 학습할 데이터가 나중에도 계속해서 추가된다면 어떻게 할까요? 기존처럼 한다면 학습시킨 모델을 버리고 처음부터 학습시키게 되는데, 훈련 데이터가 어마어마하게 크다면 리소스가 많이 소모될 것입니다. 이럴 때는 점진적으로 학습하는 알고리즘을 사용할 수 있습니다. 대표적으로 사용되는 것은 SGD입니다.
- Stochastic이라는 말은 학습을 시작할 데이터를 랜덤하게 선택한다는 의미입니다.
- Gradient라는 기울기를 통해 손실을 계산하는 것을 말합니다.
- Gradient descent라는 것은 손실을 계산해서 낮은 쪽을 따라 내려가는 것을 의미입니다.
정리하면 훈련 데이터에서 하나씩 데이터를 꺼내서 학습할 때 손실을 계산하여 낮은 쪽을 따라 학습하는 알고리즘 입니다.
SGD는 데이터를 하나씩 사용해서 손실를 줄이는 방향으로 학습합니다. 이를 반복하여 전체 데이터셋을 학습하는 것을 하나의 에포크 (epoch) 라고 합니다. 보통은 한번의 에포크가 아닌 수백번의 에포크를 거쳐야합니다. 왜냐하면 아주 조금씩 학습이 되기 때문입니다.

데이터를 하나씩 꺼내서 학습시키고 다음 경사를 따라 갑니다. 조금씩 학습하는 이유는 여기에 있습니다. 조금씩 오차를 계산할 때마다 점점 낮아지므로 다음 단계도 낮을거라는 기대를 가지고 학습하기 때문에, 학습률이 높다면 도로 올라갈 수도 있습니다.
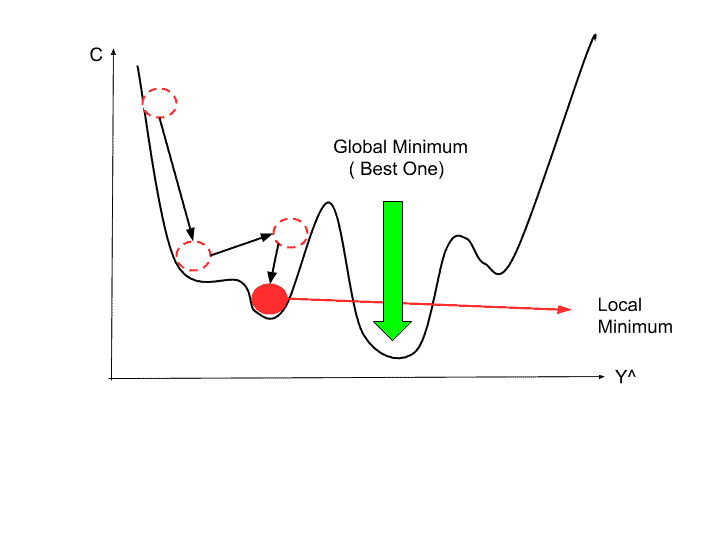
출처: https://www.mltut.com/wp-content/uploads/2020/04/Untitled-document-3.png
또한 Stochastic (확률적)이라는 것은 랜덤하게 데이터를 뽑는 것이라고 말씀드렸는데, 이는 그림에서 나타나는 문제를 보완하기 위함입니다. 랜덤으로 하지 않는다면, 우리가 이상적으로 얻고자하는 Global Minimum이 아닌 처음 찾은 Local minimum이 진짜라고 착각하고 끝내게 될 수도 있습니다.
그리고 성능을 예측하려면 지표가 필요한데, 손실함수Loss Function가 손실이 어느정도인지 계산을 해줍니다.
- Regression에서는 Mean Squeared Error (MSE)나 Mean Absolute Error (MAE)를 사용할 수 있습니다.
- Classification에서는 cross entropy loss function (logistic loss function)을 사용할 수 있습니다.
SGD에 대해 더 궁금하시다면 다음 영상도 참고해주세요.
실습
- 이번에도 classification 을 해보겠습니다.
- scikit learn에서 SGDClassifier를 제공해줍니다.
데이터 불러오기 및 전처리
1 | # 데이터 불러오기 |
SGDClassifier 모델 사용해 예측점수 확인
1 | from sklearn.linear_model import SGDClassifier |
train 데이터와 test 데이터의 점수가 낮습니다. 지금은 에포크를 10번으로 지정하여 출력한 결과입니다. 또한 아래의 경고메세지도 같이 나옵니다. 이는 모델이 충분히 수렴하지 않았다는 의미이고, 이럴 때에는 max_iter를 높여서 진행하는 것이 좋습니다.
ConvergenceWarning:
Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.mber of iteration reached before convergence. Consider increasing max_iter to improve the fit.
SGD는 점진적 학습을 하는 알고리즘이라 말씀드렸는데, partial_fit으로 모델을 이어서 훈련할 수 있습니다.
1 | # 1 에포크 추가하여 학습 |
모델의 성능이 더 좋아지는 것을 확인할 수 있습니다. 그러면 많이 학습시키면 계속해서 좋아질까요?
약 300 에포크 정도를 학습시켜보고, 훈련 데이터셋 점수와 테스트 데이터셋 점수를 비교해보겠습니다.
1 | sc = SGDClassifier(loss = "log_loss", random_state = 42) |
데이터셋이 작아서 크게 차이는 없지만 아래 그림에서 확인해보면, 100 에포크 이후로 훈련 데이터셋과 테스트 데이터셋의 성능에 차이가 나타나는 것을 볼 수 있습니다. Overfitting이 나타나는 지점으로 보입니다.
따라서, 여기서는 100 에포크까지만 학습한 모델을 예측에 사용하는 것이 좋습니다
오늘은 Logistic Regression과 Stochastic Gradient Descent에 대해 알아보았습니다. 다음에는 트리 알고리즘, 교차검증, 앙상블에 대해 정리해보겠습니다.
읽어주셔서 감사합니다.👋